突发: Karpathy 加入 Anthropic
突发: Karpathy 加入 Anthropic5 月 19 日,Andrej Karpathy 在 X 上宣布加入 Anthropic。个人近况:我已加入 Anthropic。我认为未来几年在 LLMs 前沿的工作将具有特别重要的塑造性。我非常激动能加入这里的团队并重回研发。我仍然对教育充满热情,并计划适时恢复我在这方面的工作
来自主题: AI资讯
10071 点击 2026-05-20 00:05
 搜索
搜索
5 月 19 日,Andrej Karpathy 在 X 上宣布加入 Anthropic。个人近况:我已加入 Anthropic。我认为未来几年在 LLMs 前沿的工作将具有特别重要的塑造性。我非常激动能加入这里的团队并重回研发。我仍然对教育充满热情,并计划适时恢复我在这方面的工作
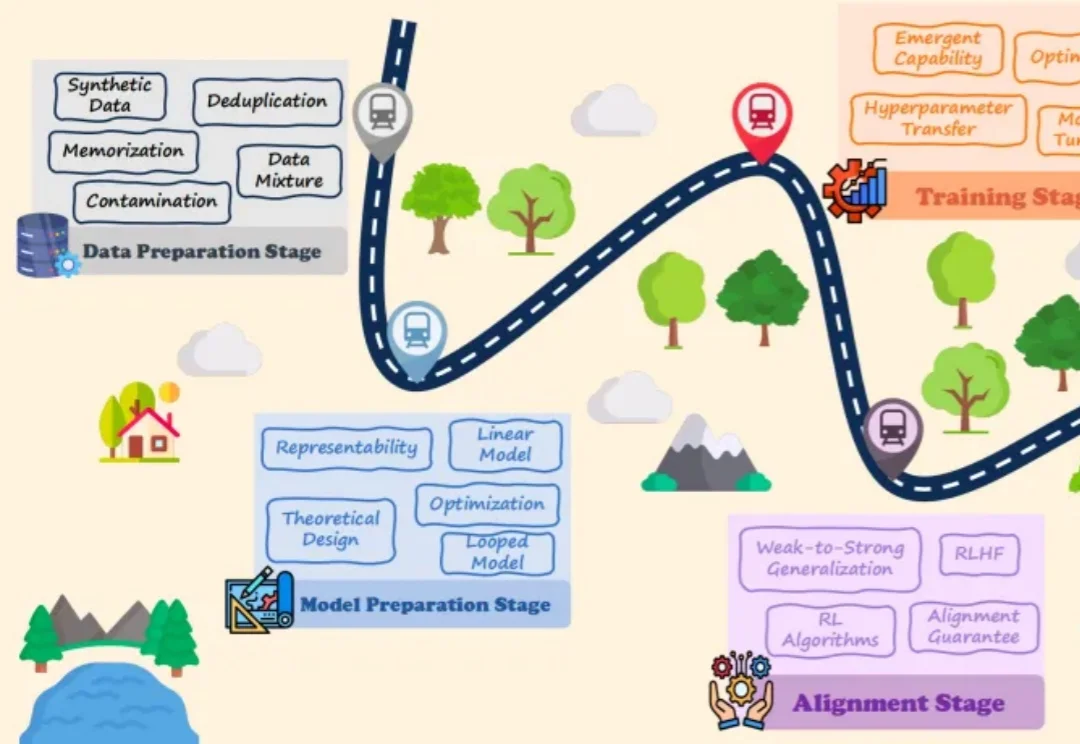
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。
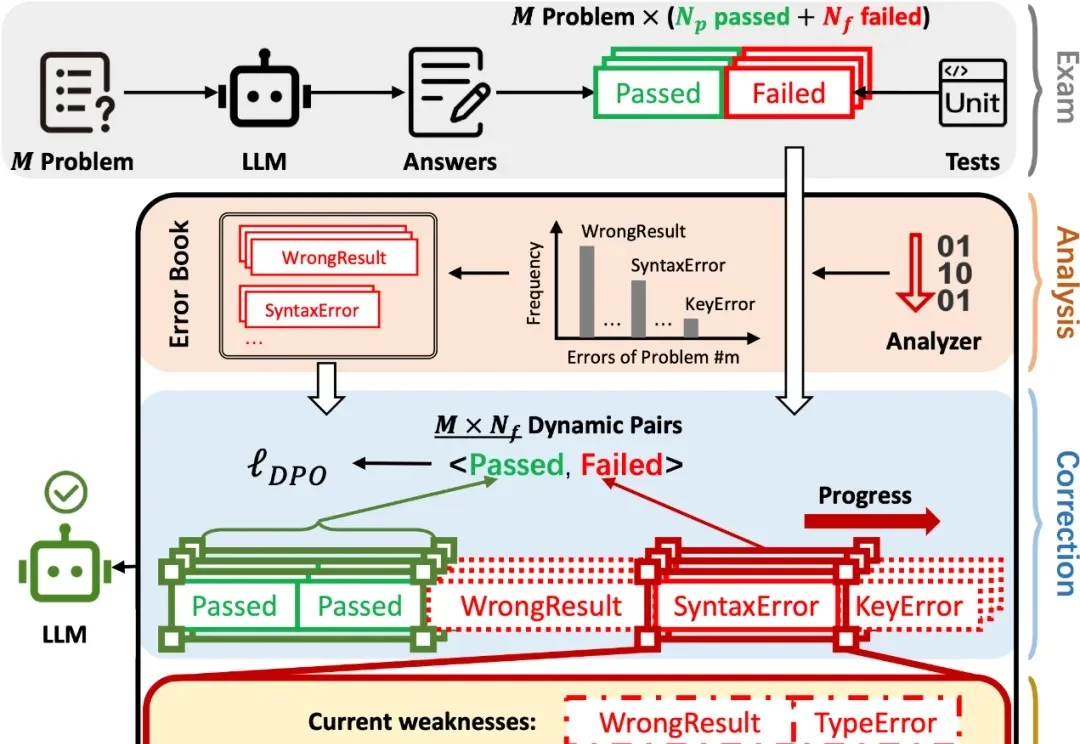
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
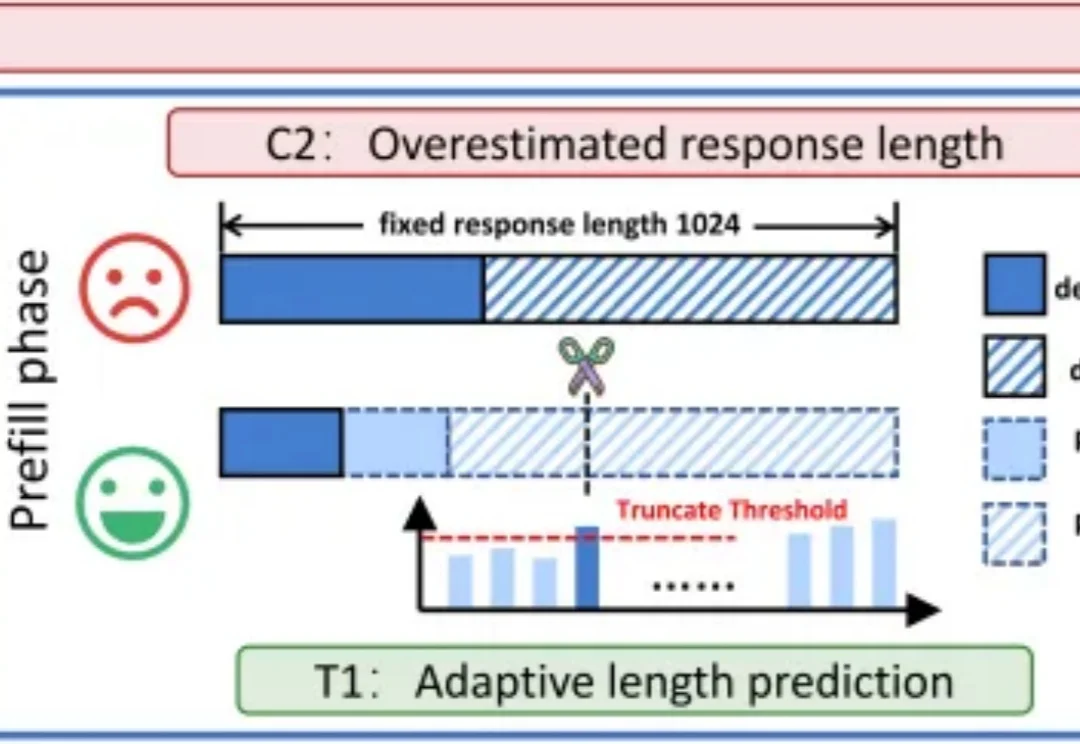
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

著名数学家陶哲轩发论文了,除了陶大神,论文作者还包括 Google DeepMind 高级研究工程师 BOGDAN GEORGIEV 等人。论文展示了 AlphaEvolve 如何作为一种工具,自主发现新的数学构造,并推动人们对长期未解数学难题的理解。AlphaEvolve 是谷歌在今年 5 月发布的一项研究,一个由 LLMs 驱动的革命性进化编码智能体。
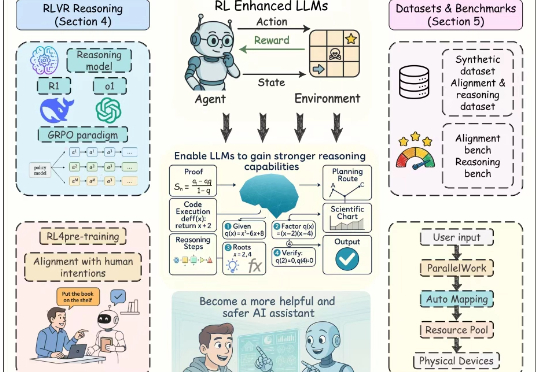
近年来,以强化学习为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理能力与对齐性能,尤其在理解人类意图、遵循用户指令以及增强推理能力方面效果突出。尽管现有综述对强化学习增强型 LLMs 进行了概述,但其涵盖范围较为有限,未能全面总结强化学习在 LLMs 全生命周期中的作用机制。

OpenRouter 创立于 2023 年初,给用户提供一个统一的 API Key,用于调用自身接入的所有模型,既包括了市面上的主流基础模型,也包括部分开源模型,一些开源模型还有多个不同的供应商。如果用户选择使用自有的 Key ,也可以同时享受 OpenRouter 的统一接口与其他服务。
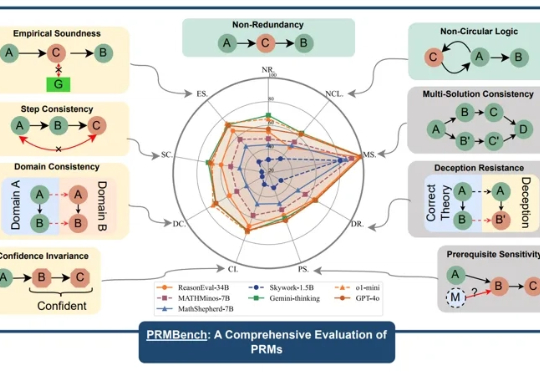
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
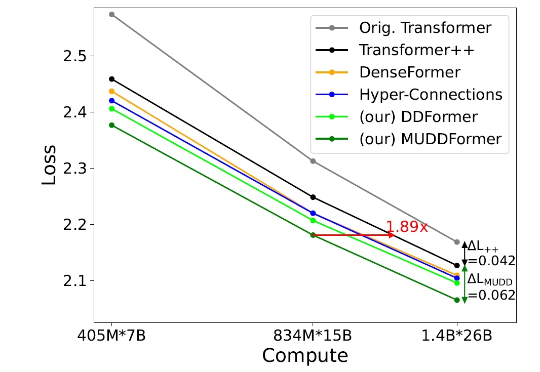
但在当今的深度 Transformer LLMs 中仍有其局限性,限制了信息在跨层间的高效传递。 彩云科技与北京邮电大学近期联合提出了一个简单有效的残差连接替代:多路动态稠密连接(MUltiway Dynamic Dense (MUDD) connection),大幅度提高了 Transformer 跨层信息传递的效率。
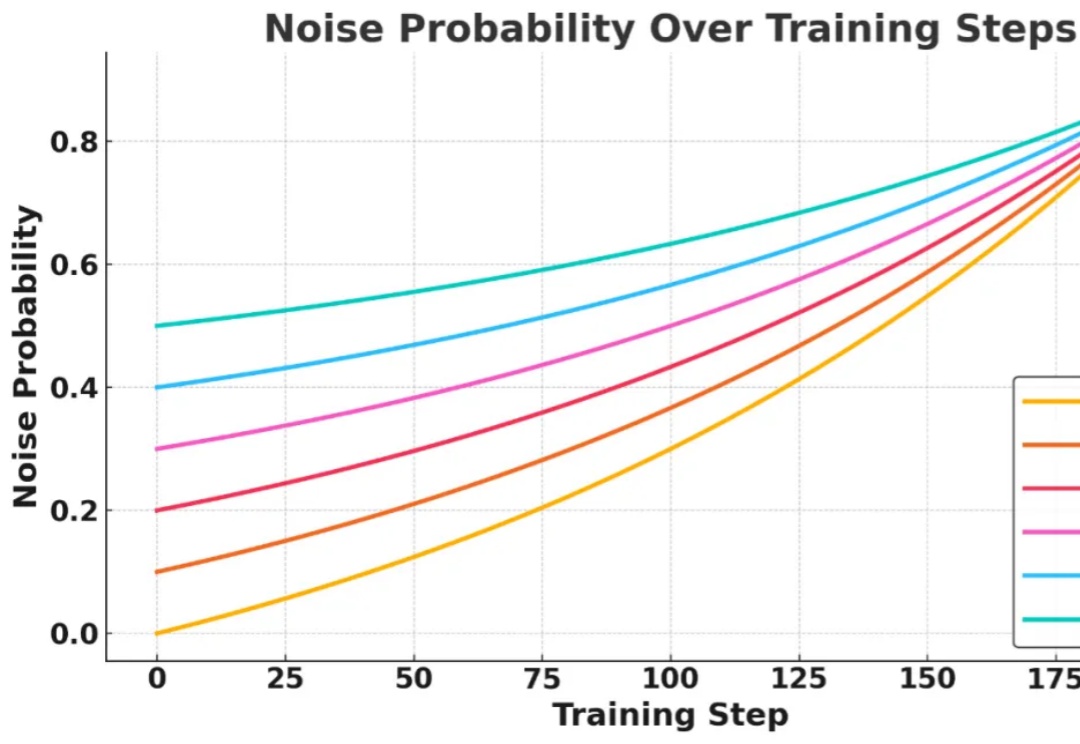
信息检索能力对提升大语言模型 (LLMs) 的推理表现至关重要,近期研究尝试引入强化学习 (RL) 框架激活 LLMs 主动搜集信息的能力,但现有方法在训练过程中面临两大核心挑战: